예전에 재미로 BBC Football Gossip 번역 봇을 하나 만들었다. 한두 달 전부터 동작하지 않는다는 건 알고 있었지만, 다른 일로 바빠서 그대로 두고 있었다.
최근 리눅스를 공부하면서 cron job을 배우게 됐고, 이 봇을 GitHub Actions 스케줄에서 Ubuntu VM의 cron job으로 옮겨서 직접 실행 환경과 로그를 관리해보면 좋은 연습이 되겠다는 생각이 들었다.
다만 마이그레이션 전에 먼저 해야 할 일이 있었다. 기존 봇이 왜 멈췄는지 확인하고, 다시 정상 동작하도록 고치는 일이었다.
간단하게 설명하면 이 봇은 BBC Football Gossip 최신 기사를 가져와서 본문 가십 문단을 추출하고, 한국어로 번역한 뒤 Slack으로 전송하는 구조다. 기존에는 GitHub Actions 스케줄을 통해 매일 실행되고 있었다.
동작하지 않았던 직접적인 원인은 BBC 페이지의 HTML 구조가 바뀌면서 기존 selector가 더 이상 기사 문단을 찾지 못했기 때문이다. 그런데 겉으로는 실행이 실패하지 않고 가십 없음으로 끝났기 때문에, 실제로는 파싱이 깨졌는데도 로그상으로는 성공처럼 보이고 있었다.
이번 작업의 핵심은 “HTML 구조 변경에 조금 더 버티고, 깨졌을 때 조용히 넘어가지 않도록 만드는 것”이었다.
1. 기존 문제
기존 코드는 BBC 기사 본문을 찾기 위해 하나의 selector에 의존하고 있었다.
하지만 현재 BBC 상세 페이지에는 div[data-component='text-block'] 구조가 더 이상 존재하지 않았다. 그 결과 문단 추출 결과가 0개가 되었고, 파이프라인은 다음처럼 정상 응답처럼 종료됐다.
이대로는 뭐가 잘못된건지 알수 없다. 실제로 가십이 없는 것인지, HTML 구조가 바뀌어 파서가 깨진 것인지 구분할 수 없기 때문이다.
2. Fallback selector 추가
먼저 selector 하나에만 의존하지 않도록 fallback selector 목록을 만들었다.
그리고 첫 번째로 매칭되는 selector를 사용하도록 변경했다.
현재 BBC 페이지 기준으로는 다음 selector가 선택된다.
selector는 여전히 HTML 구조에 의존하지만, 단일 selector보다 변경에 조금 더 강해졌다.
3. 인코딩 보정
BBC 응답에서 charset이 명확하지 않아 requests가 본문 인코딩을 ISO-8859-1로 오판하는 문제가 있었다. 그 결과 £, €, – 같은 문자가 깨질 수 있었다.
이를 막기 위해 응답 인코딩을 보정했다.
4. 내용 기준 필터 강화
문단을 찾는 것만으로는 충분하지 않았다. BBC 기사에는 가십 문단 외에도 요약 문단, 이미지 캡션, 저작권 문구 등이 포함된다.
그래서 문단의 구조뿐 아니라 내용을 기준으로 가십 여부를 판단하도록 했다.
추가한 기준은 다음과 같다.
출처가 없는 문단은 제외한다. BBC 내부 팀 링크만 있는 문단은 출처로 보지 않는다. 외부 링크가 있으면 출처 링크 후보로 본다.
back page,copyright,external linking같은 문구는 제외한다.(Mail),(The Athletic)같은 끝 괄호 출처는 본문에서 분리한다.
이 로직은 parse_gossip_paragraph()로 분리했다.
이렇게 해서 요약 문단이나 이미지 캡션이 Slack 메시지에 섞이는 문제를 줄였다.
5. 파싱 실패를 실패로 처리
가장 중요한 변경은 가십 문단이 0개일 때 더 이상 성공으로 처리하지 않는 것이다.
기존에는 다음처럼 종료됐다.
이제는 진단 로그를 남기고 예외를 발생시킨다.
실제 오늘 기사까지 가져왔는데 item이 0개라면, 그건 “정상적인 빈 결과”라기보다 파서가 깨졌을 가능성이 높다.
이제 GitHub Actions에서 실행했을 때 파싱 실패가 명확히 실패로 드러난다. 이후 cron으로 옮겨도 같은 방식으로 실패를 감지할 수 있다.
6. 실행 로그 강화
운영 중 문제가 생겼을 때 바로 원인을 볼 수 있도록 로그도 보강했다.
정상 실행 시에도 다음 정보가 출력된다.
기사 URL 기사 제목 발행일 선택된 selector 전체 문단 수 추출된 가십 item 수 selector별 매칭 수
예시 로그는 다음과 같다.
이제 실패했을 때뿐 아니라 정상 실행 중에도 현재 BBC 구조가 어떻게 해석되고 있는지 확인할 수 있다.
7. 테스트 추가
테스트는 두 종류로 나눴다.
첫 번째는 샘플 HTML 기반 테스트다. 이 테스트는 BBC 실제 사이트 변경을 감지하지는 못한다. 이 테스트의 목적은 파서 코드를 수정하다가 기존 규칙을 깨뜨렸을 때 바로 알아차리는 것이다.
예를 들어 다음을 검증한다.
출처 없는 요약 문단은 제외되는가 외부 출처 링크는 정상 추출되는가 BBC 내부 팀 링크를 출처로 오인하지 않는가 fallback selector가 의도한 순서대로 동작하는가
실행 명령은 다음과 같다.
두 번째는 실제 BBC 페이지를 가져오는 스모크 테스트다. 이 테스트는 현재 BBC 사이트 구조와 파서가 아직 맞는지 확인한다.
이 테스트는 실제 네트워크를 사용한다. 현재 기준으로는 최신 기사에서 문단 18개를 찾고, 가십 item 8개를 추출했다.
샘플 테스트는 코드 회귀 방지용이고, 스모크 테스트는 실제 BBC 구조 변경 감지용이다. 둘의 목적은 다르다.
8. GitHub Actions 반영
GitHub Actions에서도 본 실행 전에 테스트를 돌리도록 했다.
이제 파서 기본 규칙이 깨졌거나, BBC 실제 페이지에서 더 이상 문단을 추출하지 못하면 Slack 발송 전에 Actions가 실패한다.
9. 오늘 확인한 결과
로컬에서 다음 검증을 진행했다.
결과는 통과.
스모크 테스트도 통과했다.
결과는 다음과 같았다.
마지막으로 실제 앱도 DRY_RUN으로 실행했다.
결과는 정상적으로 Gossip 8개였다.
슬랙메세지도 아래와 같이 정상적으로 들어오는걸 확인할수 있다.
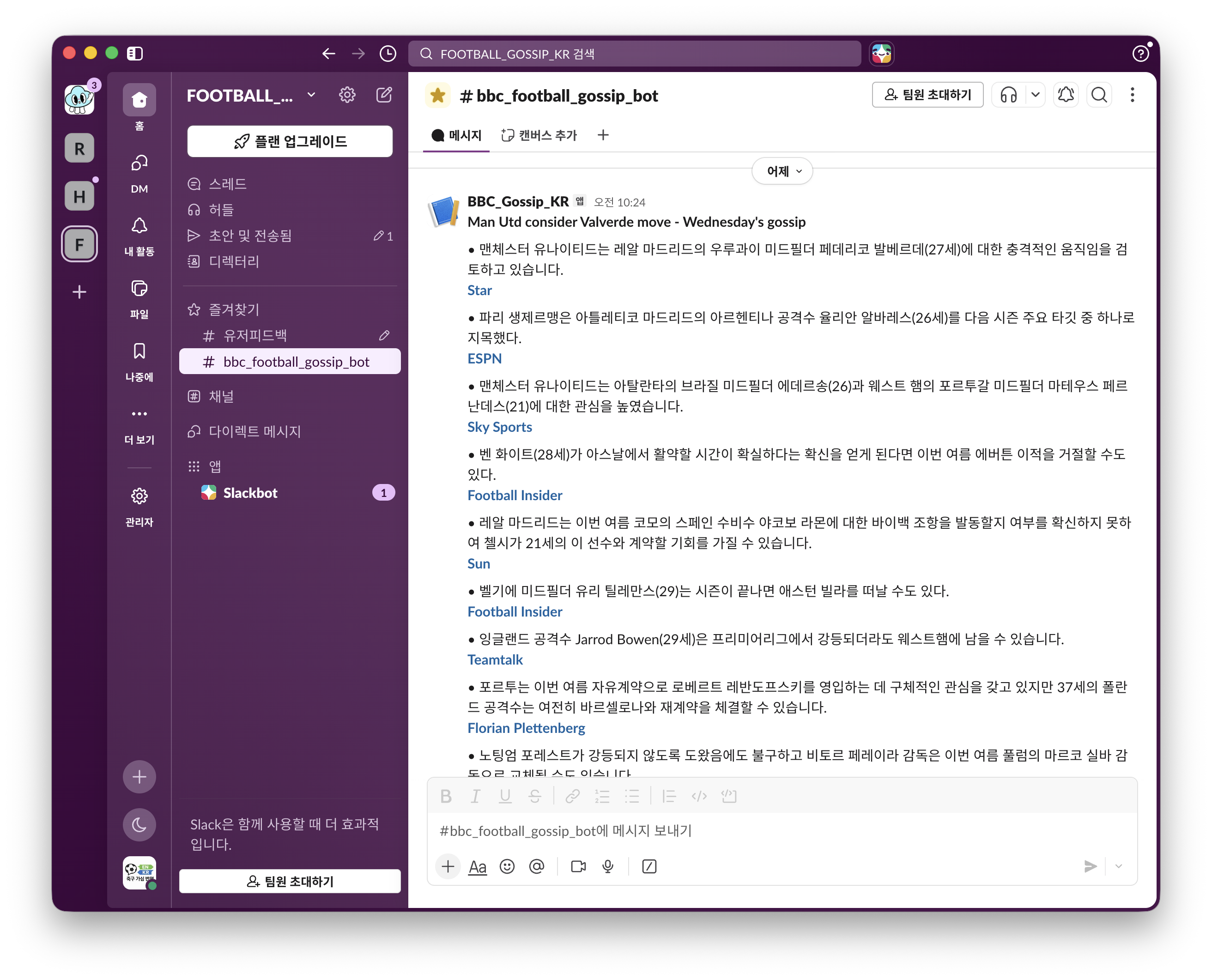
정리
이번 작업으로 BBC HTML 구조 변경에 대한 대응력이 조금 좋아졌다. 단일 selector 의존을 줄였고, 실제 페이지 기준 스모크 테스트를 추가했으며, 파싱 실패를 조용히 넘기지 않도록 했다.
물론 HTML 스크래핑 자체가 안정적인 방식은 아니다. BBC가 더 크게 구조를 바꾸면 다시 수정이 필요할 수 있다. 그래도 이제는 깨졌을 때 Slack 메시지가 조용히 누락되는 대신, 테스트나 실행 로그에서 더 빨리 알아차릴 수 있다.
다음 단계로는 GitHub Actions 기반 실행을 Ubuntu VM의 cron job으로 옮기는 작업을 할 예정이다.
작업한 코드는 아래 레포지토리에 정리되어 있다.
GitHub 레포: https://github.com/hahbr88/bbc_gossip_kr